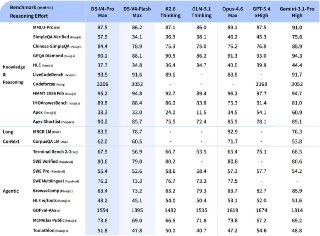
China’s DeepSeek has just released its V4-Pro and V4-Flash models, effectively turning Claude Opus-level intelligence into a commodity. With open weights and a massive one-million-token context window, the flagship V4-Pro (boasting 1.6 trillion parameters) is seizing the lead in coding and logic. To put it bluntly, this looks like a forced sterilization of profit margins for Western tech giants: charging premium API rates is becoming increasingly difficult to justify in a world where DeepSeek exists.
The engineering behind this is pragmatic. By leveraging Sparse Attention, these models can digest heavy documentation without draining your bank account. For businesses, this green-lights the use of complex agentic cascades. Previously, deploying an autonomous agent to parse intricate workflows cost dollars and gave CFOs a nervous twitch; now, the V4-Flash model (with 13 billion active parameters) shifts these tasks into the realm of pocket change. According to the developers, this cost reduction comes without sacrificing flagship-tier reasoning.
The DeepSeek team has already transitioned its own internal processes to these new models, proving their readiness for live production. While OpenAI and Anthropic build closed digital enclosures, the Chinese team is releasing SOTA tools into the wild. In doing so, they are effectively zeroing out the barriers to automating even the lowest-margin micro-tasks.
The economics of AI implementation have shifted overnight: the Total Cost of Ownership (TCO) for corporate systems is plummeting. For executives, this is a clear signal to overhaul 2025 R&D budgets. AI agent systems are no longer expensive toys for visionaries—they are now the baseline standard for operational efficiency, accessible to anyone who knows how to run a balance sheet.