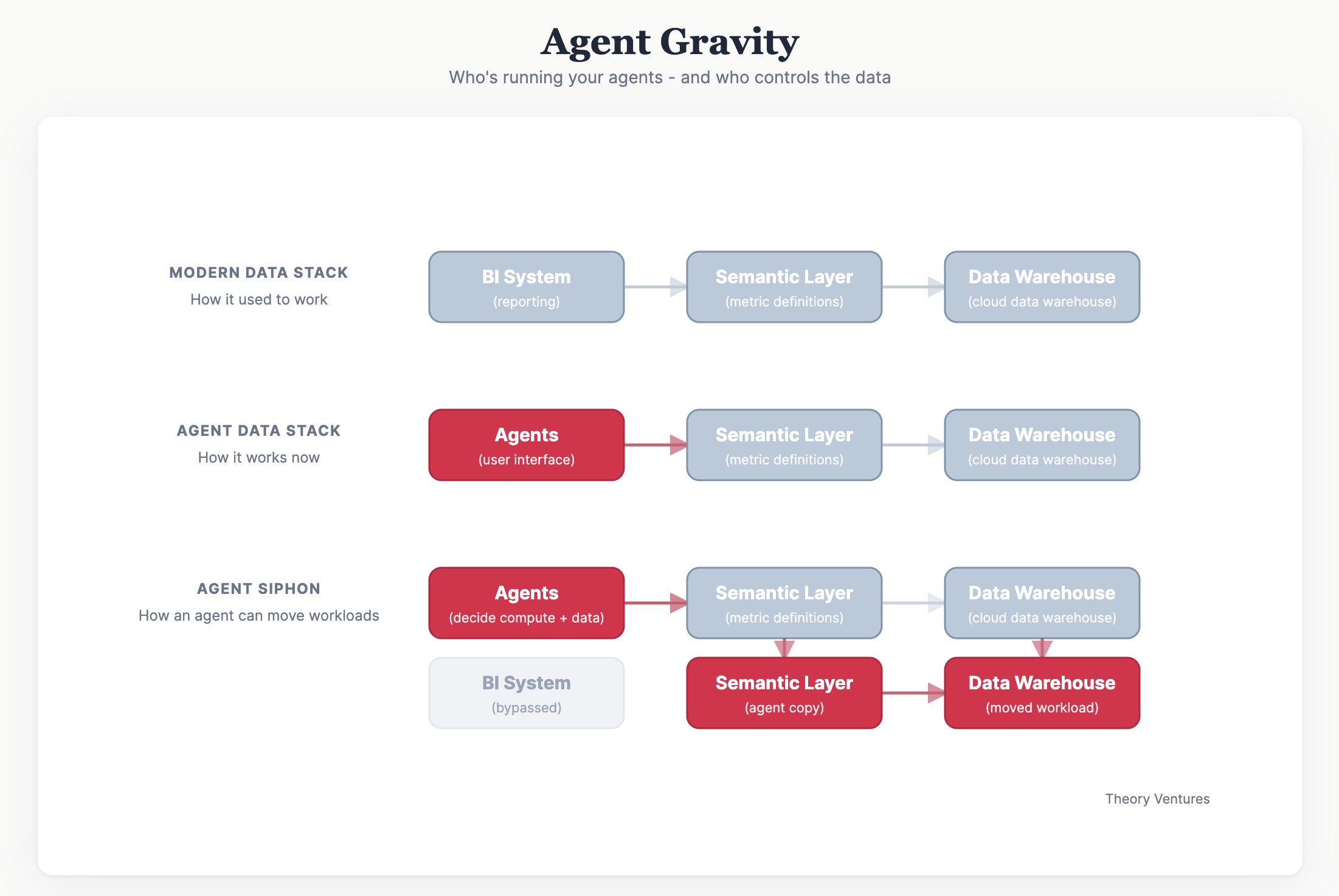
If the last decade was defined by "data gravity," the current era of AI agents introduces an even more formidable force: Agent Gravity. By their very nature, AI agents consume massive amounts of compute. This demand turns inference and execution environments into a battlefield where platforms fight to lock agent workloads within their own perimeters. The logic is simple: the more agents and data flow through a system, the stronger its pull, and the more painful it becomes for a business to switch providers.
The Battle for the Runtime
The rivalry between Databricks and Microsoft Fabric vividly illustrates how the execution environment is being weaponized. As reported by The Information, Databricks has rolled out features that simplify data management and agent creation for Power BI users. On the surface, it looks like convenience; in reality, it is a calculated maneuver to encourage building solutions within Databricks, bypassing Microsoft’s competing Fabric ecosystem.
When an agent takes over pipeline management, it is the agent's developer—or the platform itself—that decides exactly where your compute budget will be burned.
The Shift in Control
These systems are capable of extracting insights from semantic layers, moving information between cloud storage buckets, and publishing reports to external BI services. For businesses, this represents a radical shift in focus:
It no longer matters primarily where your data sits, but rather where the agent executes its logic. Companies risk discovering that their high-margin processes have quietly "migrated" to wherever agent gravity is strongest. Cost control becomes increasingly difficult due to the lack of transparency in closed ecosystems.
The critical question remains: who will truly control the decision-making logic when a platform's interest in customer retention inevitably clashes with your need for flexibility and cost optimization?