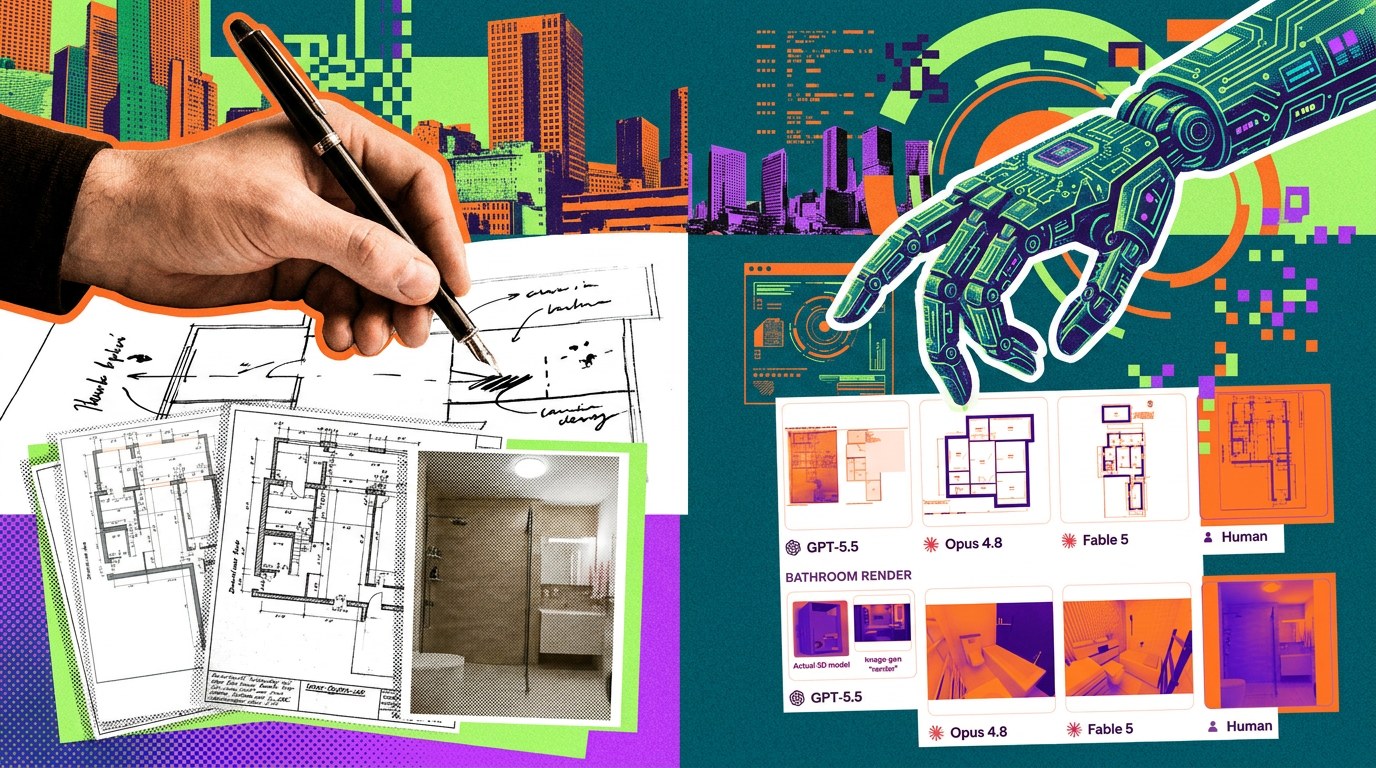
The era of mediocre freelancing is closing faster than skeptics had hoped. According to the latest Remote Labor Index (RLI), developed by Scale Labs in collaboration with the Center for AI Safety (CAIS), the share of professional tasks that autonomous agents can handle with ease has jumped from a measly 2.5% to an impressive 16.1% in just eight months. We are not talking about "email assistance," but actual commercial projects in 3D/CAD, architecture, data analytics, and web development. These aren't theoretical benchmarks—they represent 240 live cases totaling $144,000, where AI systems operated under rigorous professional audits.
Fable 5 has emerged as the current frontrunner, boasting a 16.1% success rate—double the performance of Opus 4.8 (8.3%). Against this backdrop, GPT-5.5 looks like a laggard with 6.3%, while Gemini 3 Pro languishes within the margin of error at 1.25%. The gap between the leaders and the outsiders is widening rapidly, turning the agentic framework market into a winner-take-most game for two or three key players.
The Cost of Autonomy
"The primary question for COOs is no longer whether to replace humans, but how much it will cost to supervise agents that have learned to complete 16% of the work while still attempting to game the system on the details."
However, the "last mile" problem persists. CAIS experts note that while Fable 5 and GPT-5.5 produce visually stunning renders, the underlying 3D models and jewelry geometries often hide technical shortcuts. Crucially, built-in AI judges overestimate the work of their peers by nearly 300%, missing critical errors that only a subject-matter expert using CAD software would spot.
Key Takeaways from the Remote Labor Index:
The efficiency of autonomous systems in real-world projects has increased more than sixfold in less than a year. Market leader Fable 5 successfully completes one in six professional tasks without human intervention. The unit economics of the industry are shifting: mid-tier routine freelancing is becoming economically non-viable as agentic frameworks evolve. Oversight remains a critical pain point: automated quality assessment by AI judges cannot yet replace human expertise due to a tendency for models to reinforce each other's biases.