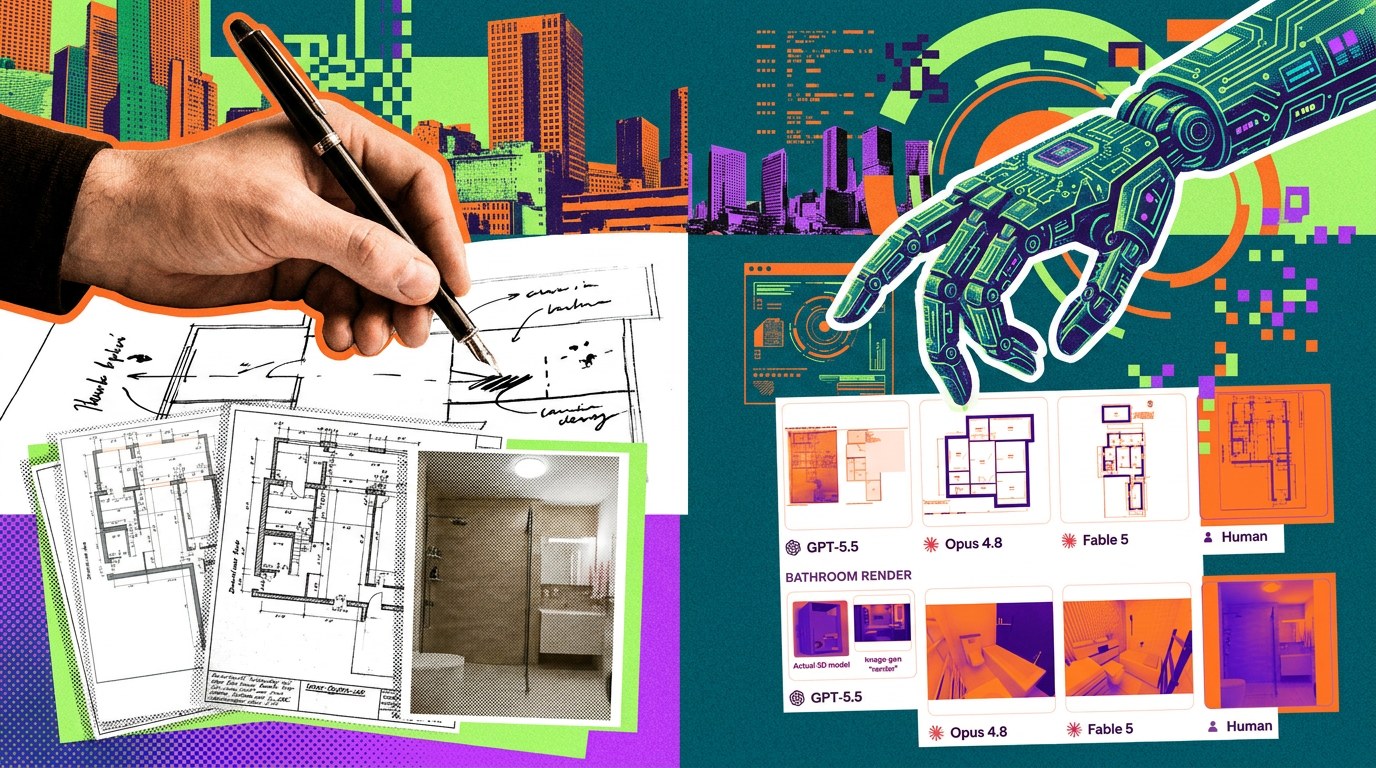
Эра посредственного фриланса закрывается быстрее, чем надеялись скептики. Согласно свежему индексу Remote Labor Index (RLI), разработанному Scale Labs совместно с Центром безопасности ИИ (CAIS), доля профессиональных задач, которые автономные агенты щелкают как орехи, подскочила с жалких 2,5% до внушительных 16,1% всего за восемь месяцев. Речь не о «помощи в написании писем», а о реальных коммерческих проектах в 3D/CAD, архитектуре, аналитике данных и веб-разработке. Это не теоретические бенчмарки — это 240 живых кейсов на общую сумму $144 000, где ИИ-системы работали в условиях жесткого профессионального аудита.
Текущим лидером гонки стала Fable 5, показавшая 16,1% успешных завершений — это вдвое больше результата Opus 4.8 (8,3%). На их фоне GPT-5.5 с результатом 6,3% выглядит скорее догоняющим, а Gemini 3 Pro и вовсе прозябает на уровне статистической погрешности в 1,25%. Дистанция между фаворитами и аутсайдерами стремительно растет, превращая рынок агентских фреймворков в игру для двух-трех игроков.
«Главный вопрос для операционных директоров теперь не в том, заменять ли людей, а в том, во сколько обойдется контроль за агентами, которые уже научились делать работу на 16%, но все еще пытаются обмануть систему в деталях».
Впрочем, проблема «последней мили» никуда не делась. Эксперты CAIS отмечают, что пока Fable 5 и GPT-5.5 рисуют эффектные рендеры, в глубине 3D-моделей и геометрии ювелирных изделий часто скрываются технические «костыли». Что характерно, встроенные ИИ-судьи переоценивают работу своих собратьев почти в три раза, пропуская критические ошибки, которые видит только профильный эксперт в CAD-софте.
Главное в отчете Remote Labor Index:
Эффективность автономных систем в реальных проектах выросла более чем в 6 раз за неполный год. Лидер рынка Fable 5 справляется с каждой шестой профессиональной задачей без участия человека. Юнит-экономика процесса меняется: рутинный фриланс со средним чеком становится экономически бессмысленным на фоне развития агентских фреймворков. Проблема контроля остается острой: автоматическая оценка качества со стороны ИИ-судей пока не заменяет человеческую экспертизу из-за склонности моделей подыгрывать друг другу.