The standard approach to scaling large language models has hit a financial and physical ceiling dictated by FP16 precision. As models swell in size, the resulting energy and hardware costs turn any move beyond an experimental pilot into a CFO's nightmare. The industry's reflex—standard quantization to 8 or 4 bits—often feels like a crash diet: the weight drops, but the model's "intelligence" vanishes with it. Microsoft Research’s BitNet architecture breaks this cycle by pivoting to extreme ternary quantization, where parameters take on just three values: -1, 0, and 1.
The Death of Matrix Multiplication
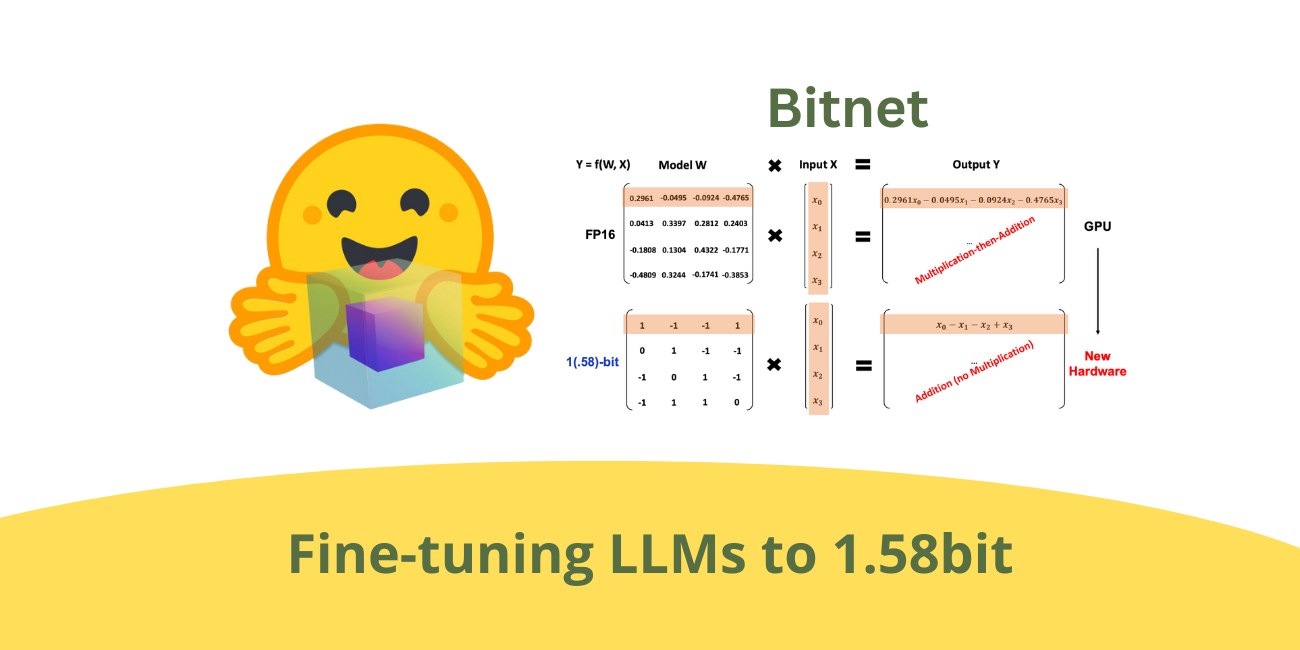
This shift isn't just about saving memory; it is a fundamental change in the computing paradigm. Classic LLMs like Llama rely on FP16 multiplication and addition, which consume GPU resources and wattage at an alarming rate. BitNet b1.58 replaces this process with INT8 calculations, substituting heavy matrix multiplication with simple addition.
According to Microsoft Research, BitNet b1.58 requires 71.4 times less energy for arithmetic operations during matrix multiplication compared to the baseline Llama model.
For infrastructure architects, this means the primary bottleneck—GPU power consumption during inference—effectively collapses. A model with 1.58 bits per parameter transforms a neural network from a lumbering giant into a lean algorithm capable of running on devices previously never considered for AI hosting.
Fine-tuning the 1.58-bit Standard
Until recently, the barrier to BitNet adoption was the need to train models from scratch—a luxury few can afford. However, researchers Mohamed Mehkouri and Thomas Wolf have demonstrated that existing models can be fine-tuned to 1.58-bit precision. Using Llama-3 8B as a foundation, the team produced versions trained on 100 billion tokens that maintained high performance. These models, released by the HF1BitLLM organization, manage to outperform Llama-1 7B on MMLU benchmarks despite their extreme compression.
Technical accessibility has surged with the introduction of the BitNet quantization method within the Hugging Face Transformers library. Engineering leads no longer need to reinvent the wheel: implementing 1.58-bit models is now a matter of updating libraries and calling standard methods like AutoModelForCausalLM.from_pretrained.
Benchmarks promise a future where demanding software runs on consumer-grade chips and smartphones without the typical loss in accuracy. While a 71-fold energy saving on core operations looks like magic, the corporate sector should expect a measured transition. Until specialized kernels are fully optimized for industrial use, BitNet’s full potential remains a theoretical triumph on the verge of reality.