Стандартный подход к масштабированию больших языковых моделей уперся в финансовый и физический потолок, заданный точностью FP16. Пока модели раздуваются в размерах, расходы на электроэнергию и железо превращают любой выход за пределы экспериментального пилота в кошмар для финансового директора. Отраслевой рефлекс — обычное квантование до 8 или 4 бит — работает как плохая диета: вес уходит, но вместе с ним исчезает и «интеллект» модели. Архитектура BitNet от Microsoft Research ломает этот сценарий, переходя к экстремальному тернарному квантованию, где параметры принимают всего три значения: -1, 0 и 1.
Смерть матричного умножения
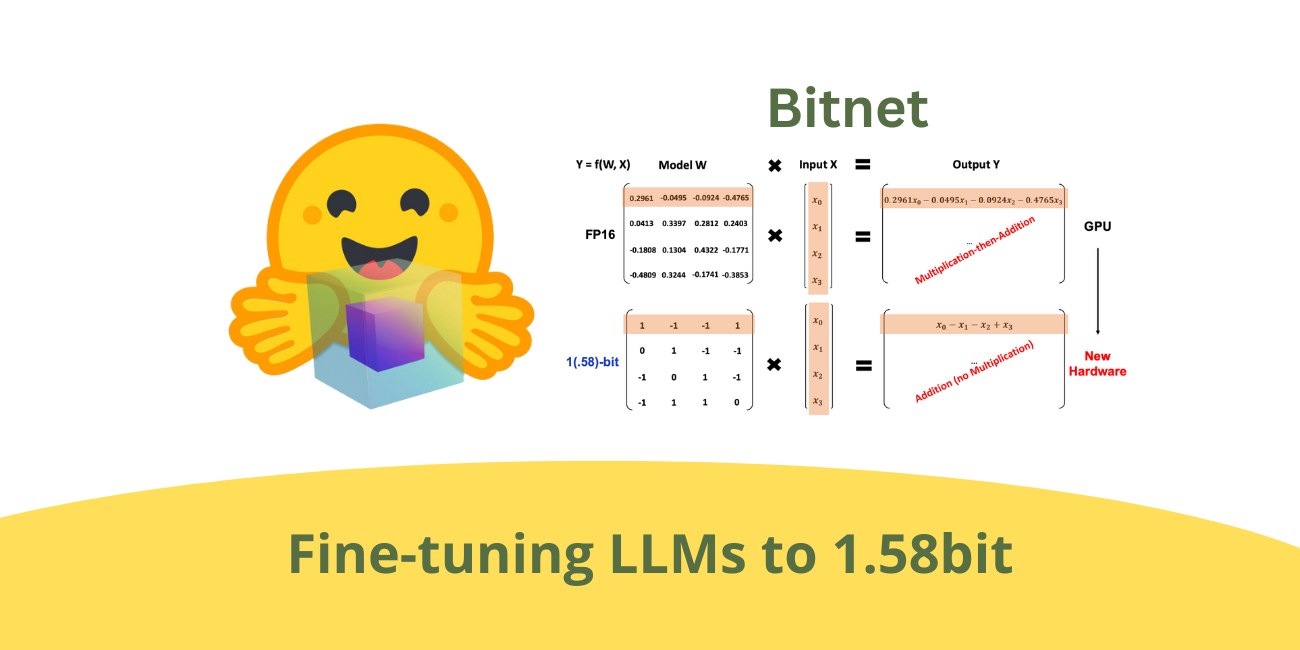
Этот сдвиг — не просто экономия памяти, а фундаментальная смена вычислительной парадигмы. Классические LLM вроде Llama полагаются на операции умножения и сложения в формате FP16, которые пожирают ресурсы GPU и ватты с пугающей скоростью. BitNet b1.58 заменяет этот процесс вычислениями INT8, где вместо тяжелого умножения матриц используется обычное сложение.
По данным Microsoft Research, BitNet b1.58 требует в 71,4 раза меньше энергии на арифметические операции при перемножении матриц по сравнению с базовой Llama.
Для архитекторов инфраструктуры это означает, что главное «бутылочное горлышко» — энергопотребление GPU при инференсе — практически схлопывается. Модель с весом 1.58 бита на параметр превращает нейросеть из неповоротливого монстра в легкий алгоритм, пригодный для работы на устройствах, которые раньше даже не рассматривались как носители AI.
Дообучение стандарта 1.58 бита
До недавнего времени барьером для внедрения BitNet была необходимость обучать модели с нуля — роскошь, доступная лишь единицам. Однако исследователи Мохамед Меккури и Томас Вольф доказали: существующие модели можно дообучить до точности 1.58 бита. Команда использовала Llama-3 8B как базу и получила версии, обученные на 100 млрд токенов, которые сохранили высокую производительность. Эти модели от организации HF1BitLLM умудряются обходить Llama-1 7B в бенчмарках MMLU, несмотря на экстремальное «сжатие».
Техническая доступность решения резко выросла с появлением метода квантования bitnet в библиотеке Transformers от Hugging Face. Теперь техническим лидам не нужно изобретать велосипед: внедрение 1.58-битных моделей сводится к обновлению библиотек и вызову стандартных методов вроде AutoModelForCausalLM.from_pretrained.
Бенчмарки сулят будущее, где тяжелый софт запускается на потребительских чипах и смартфонах без привычной потери точности. И хотя 71-кратная экономия энергии на базовых операциях выглядит как магия, в реальности корпоративный сектор ждет умеренно быстрый переход — пока специализированные ядра не будут полностью оптимизированы для промышленной эксплуатации, потенциал BitNet останется в плоскости теоретического триумфа.