The engineering challenge of million-token contexts has long been hindered by the quadratic complexity of the standard Transformer. While competitors attempt to solve the problem by throwing hardware and raw compute at it, the DeepSeek-AI team has introduced the DeepSeek-V4 series—two preview models based on a Mixture-of-Experts (MoE) architecture that treat parameter efficiency as a core philosophy. The flagship DeepSeek-V4-Pro, with a total weight of 1.6T parameters, activates only 49B, while the nimble DeepSeek-V4-Flash manages with a modest 13B out of 284B. By training these models on a massive 32-trillion-token dataset, DeepSeek has demonstrated that trillion-scale intelligence can be packed into a 'small-scale' computational budget, effectively decoupling model depth from the financial abyss of inference costs.
Solving the Density Crisis via Hybrid Attention
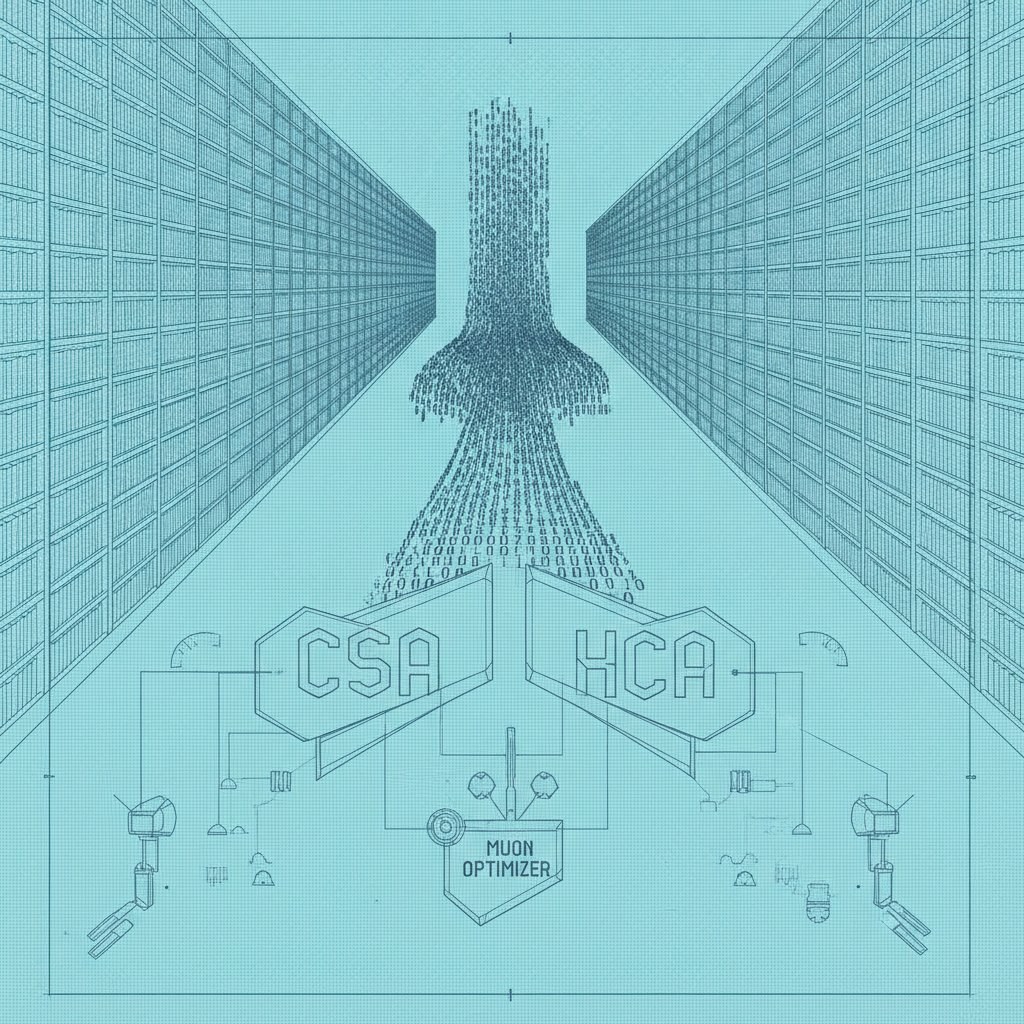
To digest data within a million-token window, DeepSeek-V4 moves away from uniform attention mechanisms. It utilizes a hybrid architecture combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). This architectural maneuver bypasses the linear memory bloat that typically prevents the large-scale implementation of long contexts. According to DeepSeek-AI researchers, DeepSeek-V4-Pro requires only 27% of the compute (FLOPs) per token generation compared to its predecessor, V3.2.
When processing a million tokens, DeepSeek-V4-Pro requires just 10% of the KV cache volume compared to DeepSeek-V3.2. This nearly tenfold reduction in cache size directly addresses the physical limits of GPU memory. By compressing the 'memory' of past tokens, DeepSeek transforms long-horizon planning from a laboratory curiosity into a routine operational reality.
To maintain stability at this scale, engineers implemented Manifold-Constrained Hyper-Connections (mHC). This reimagining of classic residual connections is essential for training ultra-deep networks; mHC ensures structural integrity and protects against signal decay or gradient instability—issues that often cause massive models to stumble.
Convergence Economics: Muon and Expert Parallelism
Training efficiency is the second front in DeepSeek’s gambit. The introduction of the Muon optimizer has radically accelerated model convergence and ensured process stability on the giant 32T token dataset. The tech stack, optimized for expert parallelism, isn't just for show: it is a direct method for reducing the Total Cost of Ownership (TCO) when training and operating models with deep reasoning logic.
Flagship performance: DeepSeek-V4-Pro-Max reaches 57.9% in SimpleQA and a 3206 rating on Codeforces. Architectural trade-offs: Aggressive HCA usage can reduce the recall of fine details compared to classic dense models. Business impact: Million-token intelligence is shifting from an expensive luxury to accessible infrastructure.
The era of simply scaling up compute is giving way to the era of 'smart paths,' making deep-reasoning agents economically viable for mass corporate scenarios.