Инженерный вызов миллионного контекста долгое время упирался в квадратичную сложность стандартного Transformer. Пока конкуренты пытаются залить проблему «железом» и сырыми вычислениями, команда DeepSeek-AI представила серию DeepSeek-V4 — две превью-модели на архитектуре Mixture-of-Experts (MoE), которые возводят эффективность параметров в культ. Флагманская DeepSeek-V4-Pro при общем весе в 1.6T параметров активирует лишь 49B, а юркая DeepSeek-V4-Flash с ее 284B обходится скромными 13B. Обучив модели на массиве из 32 трлн токенов, DeepSeek наглядно доказали: интеллект уровня триллионника можно упаковать в вычислительный бюджет «малыша», фактически отвязав глубину модели от финансовой бездны инференса.
Решение кризиса плотности через гибридное внимание
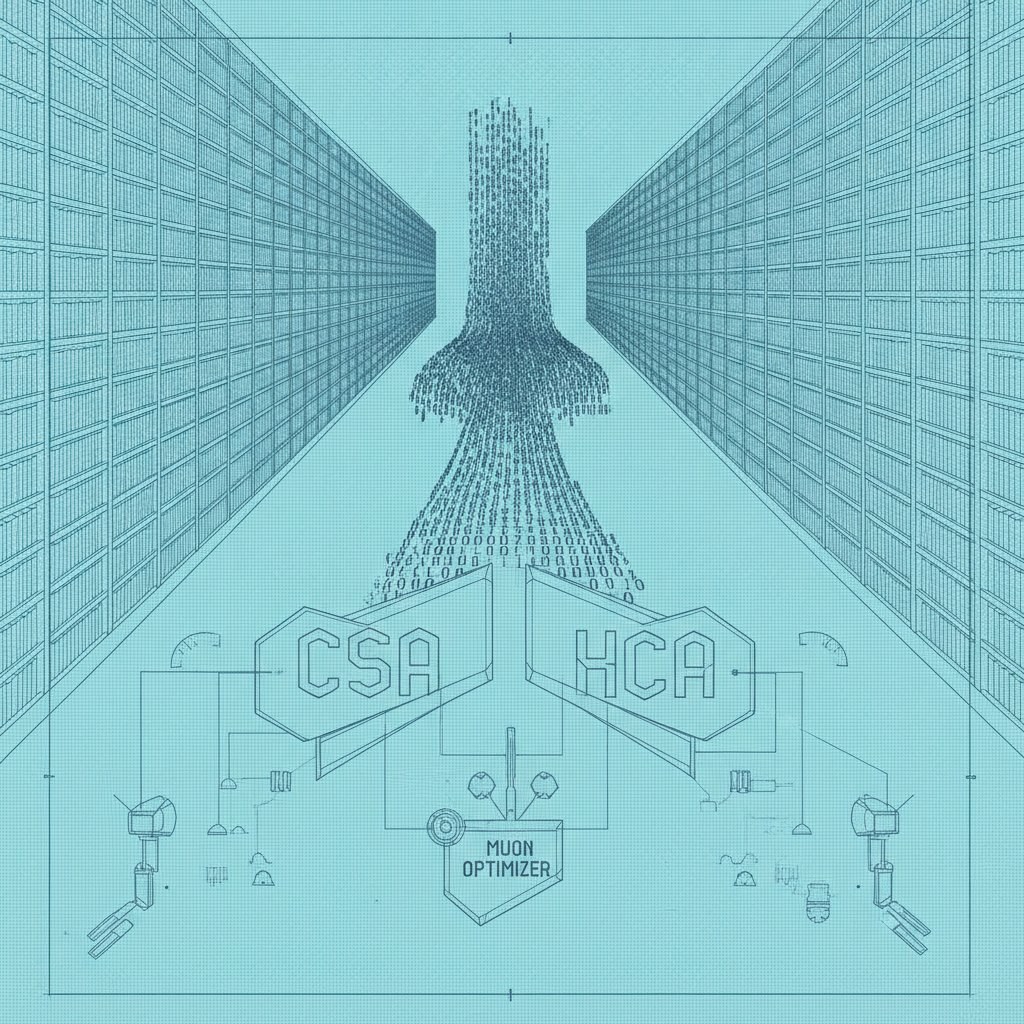
Чтобы переварить данные в окне в миллион токенов, DeepSeek-V4 отказывается от однородных механизмов внимания. В основе лежит гибридная архитектура, сочетающая сжатое разреженное внимание (Compressed Sparse Attention, CSA) и экстремально сжатое внимание (Heavily Compressed Attention, HCA). Этот архитектурный финт позволил обойти проблему линейного раздувания памяти, которое обычно ставит крест на масштабном внедрении длинных контекстов. По данным исследователей DeepSeek-AI, DeepSeek-V4-Pro требует всего 27% вычислительных мощностей (FLOPs) на генерацию одного токена по сравнению со своей предшественницей V3.2.
В условиях работы с миллионом токенов DeepSeek-V4-Pro требует лишь 10% объема KV-кэша по сравнению с DeepSeek-V3.2. Это почти десятикратное сокращение размера кэша напрямую решает проблему физических лимитов видеопамяти GPU. Сжимая «память» о прошлых токенах, DeepSeek превращает работу с длинными горизонтами планирования из лабораторного экзотики в рутинную операционную реальность.
Для поддержания стабильности в таких масштабах инженеры внедрили гиперсвязи с ограничениями на многообразии (Manifold-Constrained Hyper-Connections, mHC). Это переосмысление классических остаточных связей (residual connections) необходимо для обучения сверхглубоких сетей: mHC гарантирует структурную целостность и страхует от затухания сигналов или градиентной нестабильности, на которых часто «спотыкаются» массивные модели.
Экономика сходимости: Muon и экспертный параллелизм
Эффективность обучения — второй фронт в гамбите DeepSeek. Внедрение оптимизатора Muon позволило радикально ускорить сходимость модели и обеспечить стабильность процесса на гигантском датасете в 32T токенов. Технологический стек, заточенный под экспертный параллелизм, здесь работает не для красоты: это прямой способ снижения совокупной стоимости владения (TCO) при обучении и эксплуатации моделей с глубокой логикой рассуждений.
Результаты видны в режиме максимальных рассуждений DeepSeek-V4-Pro-Max: 57.9% в SimpleQA и рейтинг 3206 на Codeforces. Однако архитектурное сжатие — это всегда компромисс. Агрессивное использование HCA может снижать точность извлечения (recall) мелких деталей по сравнению с классическими плотными моделями. Для бизнеса это сигнал: интеллект с миллионным контекстом превращается из дорогой игрушки в доступную инфраструктуру. Эпоха наращивания вычислительных мощностей уступает место эпохе «умных путей», делая агентов с глубоким рассуждением экономически целесообразными для массовых корпоративных сценариев.