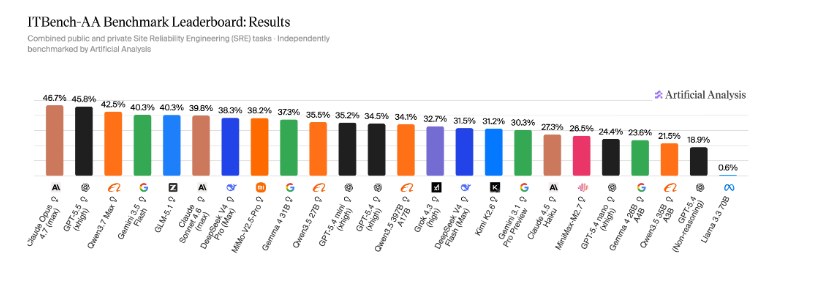
Flagship AI models have hit a "glass ceiling" in their attempt to move beyond simple chatbots into real-world operations. While marketing departments paint a future of autonomous DevOps engineers, fresh data from the ITBench-AA benchmark brings us back to earth: not a single existing system is capable of closing even half of typical Site Reliability Engineering (SRE) tasks. According to a report by Artificial Analysis and the IBM Software Innovation Lab, Claude Opus 4.7 in its maximum reasoning mode leads with a dismal score of 47%. It is followed by GPT-5.5 at 46% and Qwen 3.7 Max at 42%. This is one of the industry's most "uncomfortable" tests: it proves that high scores in logic puzzles or writing Python code do not translate into the ability to manage live Kubernetes infrastructure.
The Kubernetes Litmus Test
The reason for the failure lies in the extreme complexity of the modern IT landscape. ITBench-AA simulates K8s incidents, requiring the agent to do more than just "fix" a bug; it must diagnose the system by reading logs, tracing dependency chains, and identifying the root cause within the application topology. The dataset, prepared by IBM experts, includes operational "joys" such as resource quota exhaustion, rollout failures, and network partitions. The evaluation methodology revealed a critical defect in agent "thinking": models regularly mistake symptoms or side effects for the true cause of an outage, resulting in false-positive diagnoses.
All frontier models scored below 50%, making ITBench-AA SRE one of the most challenging tests for agentic systems to date.
The chasm between reasoning ability and the capacity to act is best seen in the models' own work logs. Researchers from Artificial Analysis discovered a paradox: prolonged "thinking" and a higher number of iterations do not correlate with accuracy. For instance, Gemini 3.1 Pro Preview averaged 83 steps per task but succeeded only 30% of the time. Meanwhile, Gemma 4 31B handled tasks in fewer iterations with a 37% success rate. As the study authors note, models prone to excessive "overthinking" simply drown in information noise, mistaking secondary signals for the core issue. For critical infrastructure, this is a direct risk: an autonomous agent might misinterpret a problem and trigger an automated "fix" that ultimately crashes the cluster.
The Economics of Oversight
The shift from fantasies of full automation to strictly controlled "co-piloting" is now a business necessity, not a choice. Even open-source models like GLM-5.1 show a competitive 40%, but they are nowhere near the reliability required to be handed the keys to production. DeepSeek V4 Pro’s result of 38% confirms that without human oversight, these systems cannot be trusted in the cloud. The key takeaway for CTOs: currently, agentic systems are merely advanced diagnostic assistants, not independent operators. While the benchmark plans to expand into FinOps and CISO tasks, the current "agent tax"—the time a human spends verifying and correcting AI hallucinations—remains prohibitively high.
Audit your AI implementation plans: any autonomous recovery scripts at critical nodes must be blocked until a human engineer is required to sign off on the system's diagnosis within the decision-making loop.