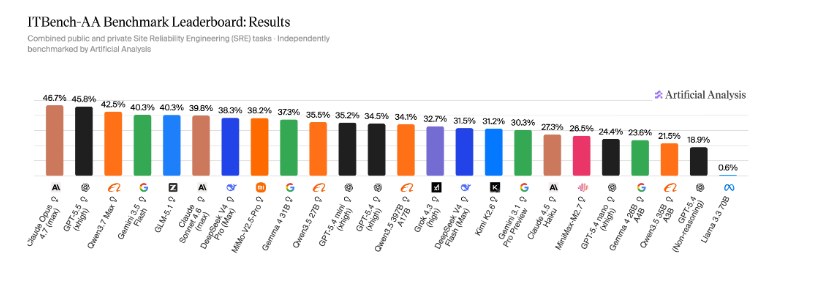
Флагманские ИИ-модели уперлись в «стеклянный потолок» при попытке выйти за пределы чат-ботов в реальную эксплуатацию. Пока маркетинговые отделы рисуют картины будущего с автономными DevOps-инженерами, свежие данные бенчмарка ITBench-AA возвращают нас на землю: ни одна из существующих систем не способна закрыть даже половину типичных задач по обеспечению отказоустойчивости (SRE). Согласно отчету Artificial Analysis и лаборатории IBM Software Innovation Lab, Claude Opus 4.7 в режиме максимальных рассуждений лидирует с жалким результатом в 47%. За ним следуют GPT-5.5 с 46% и Qwen 3.7 Max, набравшая 42%. Это один из самых «неудобных» тестов в индустрии: он доказывает, что высокие баллы в логических задачках или написании кода на Python абсолютно не конвертируются в способность управлять живой инфраструктурой Kubernetes.
The Kubernetes Litmus Test
Причина фиаско кроется в запредельной сложности современного IT-ландшафта. ITBench-AA имитирует инциденты в K8s, требуя от агента не просто «починить», а диагностировать систему: читать логи, отслеживать цепочки зависимостей и вычленять первопричину в топологии приложений. Набор данных, подготовленный экспертами IBM, включает такие «радости» эксплуатации, как исчерпание квот ресурсов, сбои при раскатке обновлений и сетевые разделения. Методология оценки вскрыла критический дефект в «мышлении» агентов: модели регулярно принимают симптомы или побочные эффекты за истинную причину аварии, выдавая ложноположительные диагнозы.
Все фронтирные модели набрали менее 50%, что делает ITBench-AA SRE одним из самых сложных испытаний для агентных систем на сегодняшний день.
Пропасть между способностью рассуждать и способностью действовать лучше всего видна в логах работы самих моделей. Исследователи из Artificial Analysis обнаружили парадокс: длительные раздумья и количество итераций никак не коррелируют с точностью. Например, Gemini 3.1 Pro Preview тратила в среднем 83 шага на задачу, но достигала успеха лишь в 30% случаев. В то же время Gemma 4 31B справлялась за меньшее число итераций с результатом 37%. Как отмечают авторы анализа, модели, склонные к чрезмерному «самокопанию», попросту тонут в информационном шуме, принимая вторичные признаки за основу. Для критической инфраструктуры это прямой риск: автономный агент может ошибочно интерпретировать проблему и запустить автоматическое «исправление», которое окончательно добьет кластер.
The Economics of Oversight
Переход от фантазий о полной автоматизации к жестко контролируемому «со-пилотированию» — теперь не выбор, а производственная необходимость. Даже открытые модели вроде GLM-5.1 показывают конкурентные 40%, но они бесконечно далеки от надежности, позволяющей выдать им ключи от продакшена. Результаты DeepSeek V4 Pro на уровне 38% подтверждают: без надзора человека такие системы в облако пускать нельзя. Главный вывод для CTO: сейчас агентные системы — это лишь продвинутые ассистенты для диагностики, но никак не самостоятельные операторы. Бенчмарк планируют расширить на задачи FinOps и CISO, однако текущий «агентный налог» — время, которое человек тратит на проверку и исправление галлюцинаций ИИ — остается запредельно высоким.
Проведите аудит ваших планов по внедрению ИИ: любые скрипты автономного восстановления в критических узлах должны быть заблокированы до тех пор, пока в контуре принятия решений не появится обязательная подпись живого инженера, подтверждающего диагноз системы.