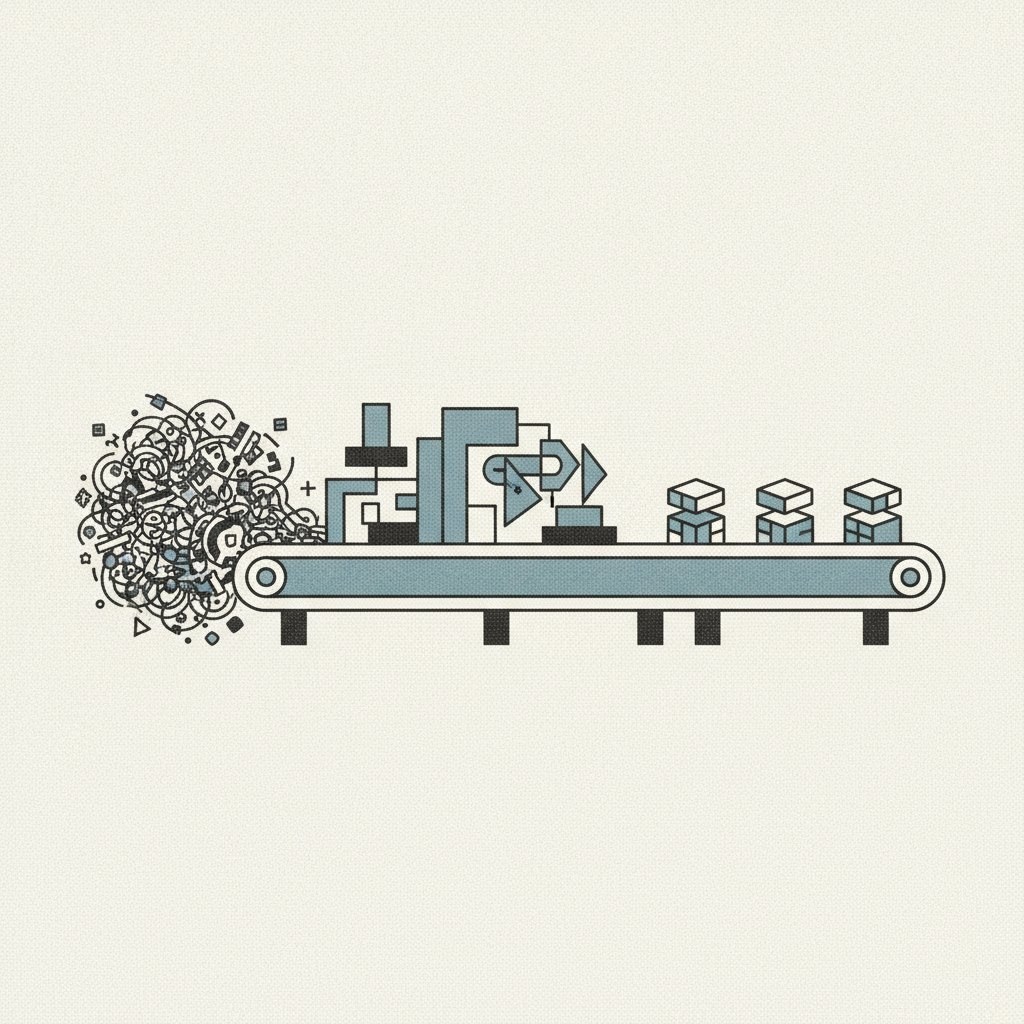
Прямой проброс вопроса клиента в LLM на демо выглядит как магия, но в реальности быстро превращается в проект, который просто съедает деньги и уничтожает лояльность аудитории. По данным разработчиков системы FinlogiQ AI Support, наивный подход к RAG заставляет компанию оплачивать каждое «спасибо» и «здравствуйте» по тарифу топовых нейросетей, пока те галлюцинируют на пограничных сценариях. Бизнесу не нужен «интеллект» там, где достаточно регулярного выражения, — ему нужна предсказуемость.
Переход к архитектуре жесткого конвейера меняет правила игры: нейросеть вызывается в последнюю очередь. В FinlogiQ внедрили доменную модель ContactReason со строгими маркерами — фразовыми масками, числовыми тегами и весами. Это позволяет закрывать типовые обращения на уровнях L0 и L1 вообще без участия тяжелых моделей. Если алгоритм видит точное совпадение с эталоном ответа (ExampleQA) с порогом 0.7 и выше, бот отвечает мгновенно. Главное здесь — отсутствие задержки и нулевой риск того, что модель придумает несуществующую функцию продукта.
Механика предельно прагматична: вместо того чтобы гадать, о чем спросил пользователь, система сначала проверяет критические признаки — скрытые угрозы или требование переключить на человека. Затем включается скоринг: фразовая маска весит 10 баллов, а глагол — всего 1. Если данные зашумлены, LLM используется лишь как «санитар» для нормализации текста, но не для генерации ответа. Это превращает хаотичный чат в управляемую маршрутизацию, где каждый токен работает на юнит-экономику, а не на фантазии алгоритма.
Наш вердикт: без жесткой бизнес-логики и многослойных фильтров «умный» бот лишь быстрее масштабирует убытки. Инженерная дисциплина сегодня важнее, чем количество параметров в модели, а умение вовремя «выключить» нейросеть в пользу классического кода становится главным признаком здорового AI-внедрения.