Современный бизнес попал в зависимость от облачных вычислений, переплачивая за избыточные мощности там, где в них нет реальной необходимости. Эксперимент венчурного инвестора Тома Тунгуза расставляет точки над i: за пять недель и 1476 запросов к нейросетям выяснилось, что ровно половина рабочих задач не требует гигантских моделей с триллионами параметров. В структуре нагрузки доминируют рутинные операции: на планирование встреч ушло 17,2%, на рыночные исследования — 13%. Когда 50% вашего рабочего дня занимают суммаризация текстов, администрирование и несложный инжиниринг, отправлять эти данные в облако — всё равно что ездить за хлебом на карьерном самосвале.
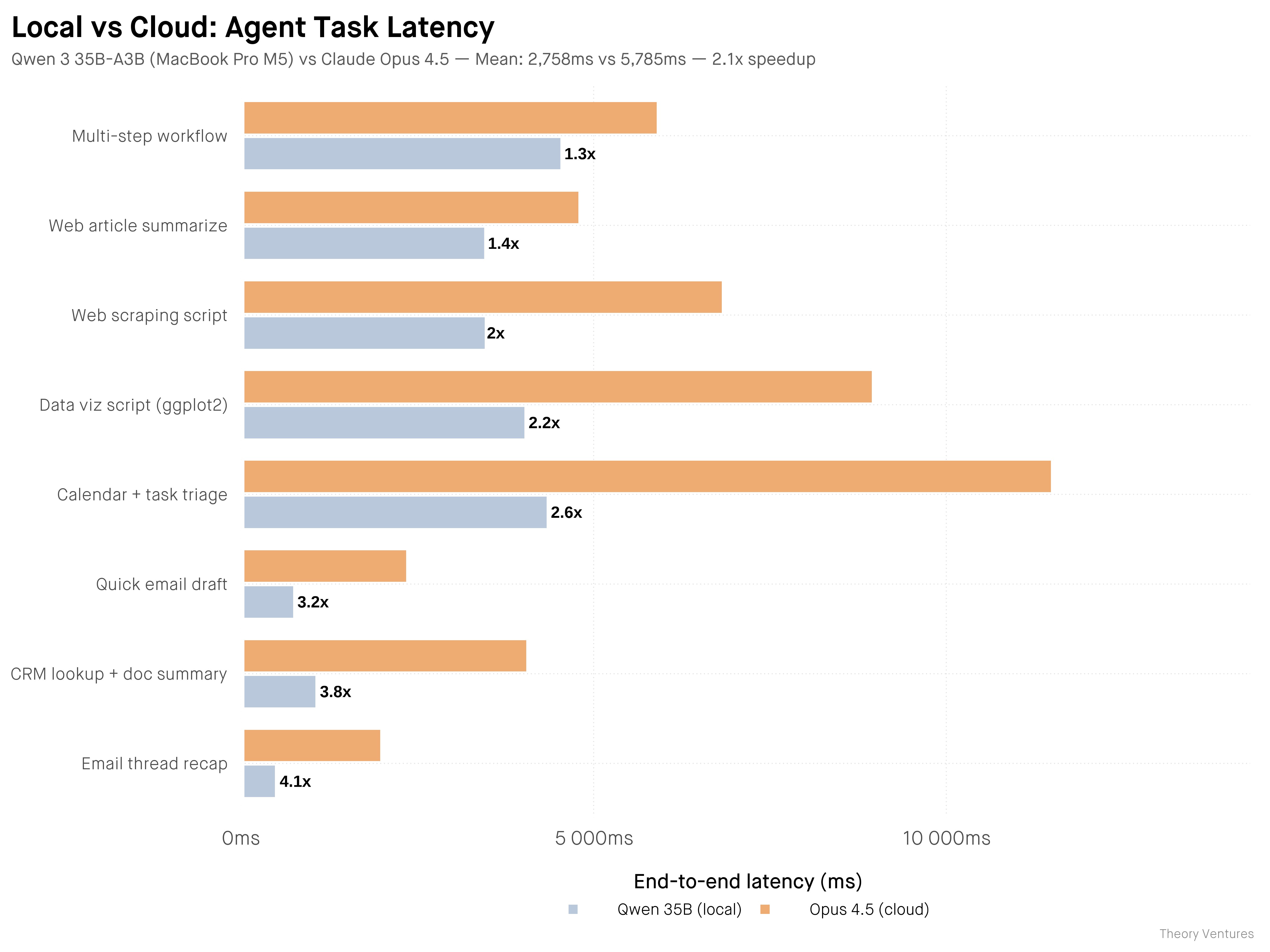
Экономика перехода на малые языковые модели (SLM) предельно прагматична: это отказ от «налога на токены» в пользу эффективной эксплуатации собственного оборудования. Как отмечает Тунгуз, ваш MacBook Pro на чипе M-серии обесценивается ежедневно, используете вы его нейронный движок или нет. Запуск локальной модели позволяет извлекать ценность из актива, который иначе просто простаивает. Сравнение модели Qwen 35B на локальном железе и Claude через API показало, что домашнее решение справляется в два раза быстрее. Да, топовые модели вроде Opus 4.5 всё еще обходят локальных конкурентов в логике примерно на 20%, но для агентских задач, где важны лаконичность и скорость передачи данных в другие системы, избыточное «красноречие» облачных гигантов становится лишь лишней тратой времени и денег.
Информационная безопасность здесь выступает не просто как маркетинговый лозунг, а как гигиенический минимум. Локальный инференс — единственный способ работать с чувствительной информацией (сделки слияния и поглощения, конкурентная разведка, внутренние транскрипты) без риска, что ваши секреты утекут в обучающую выборку очередного ИТ-гиганта. Пока индустрия убеждала нас, что интеллект живет только в огромных кластерах, реальность доказала обратное: локальные опенсорс-решения вроде Llama или Mistral сократили отставание от флагманских моделей до считанных месяцев.
Для ИТ-директоров и владельцев бизнеса в 2024 году это означает смену парадигмы. Бюджеты на ИИ должны перетекать из бесконечных облачных подписок в развитие собственной инфраструктуры и оптимизацию малых моделей под конкретные отраслевые задачи. Мы наблюдаем закат эпохи универсальных гигантов. Наступает время специализированных стеков, работающих внутри корпоративного контура. Половина вашей работы может и должна выполняться на устройстве, которое уже стоит у вас на столе — быстрее, приватнее и, главное, бесплатно.